How Do I Enable Support for Multilingual Data? (Magic xpa 3.x)
Magic xpa has excellent support for multilingual data. Internally, Magic xpa uses Unicode format when possible, and it has tools to allow you to translate between Unicode and other representations.
However, in order to work with Unicode on your computer, you need to be sure your computer is set up to support Unicode correctly. In the United States, at least, current computers do not install the full Unicode font set by default, so you will not be able to view Unicode characters.
Also, Unicode data needs to be displayed in a field with a Unicode attribute type, that is using the Unicode font.
In this section, we will deal with these issues.
Back in the days of Ascii, all characters could fit within one byte. This was mainly because the first programmers mostly spoke English, which has a mere 26 characters in the alphabet, leaving plenty of room for special characters. However, the “special characters” were mapped out differently depending on the usage, so, Ascii code 210 could mean a funny looking E, funny looking O, or graphic line character, depending on the “code page” being used.
In order to get around this issue, Unicode was invented. Unicode essentially combines all the world’s alphabets into one big code page with many thousands of characters. You can find the mapping of these characters online, at www.unicode.org. There you will find that the original Ascii fonts, 0 thru 128, are mapped as they always have been, but other more esoteric characters have been added. For instance, hex code 30B0 is the Japanese character below.

Other hex codes exist for other languages, both existing, historical, and fictional (Klingon characters are in there too).
This is very good in theory, but it makes for a large Windows font. As a result, many Windows systems do not have a Unicode font installed for you to view these Unicode characters. One good Unicode font comes with Microsoft Office, Arial Unicode MS, but it is not installed by default when you install Microsoft Office. Follow the directions at http://office.microsoft.com/en-ca/assistance/HP052558401033.aspx to install it.
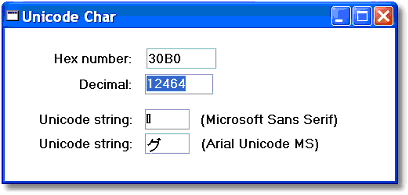
If you are displaying characters in one particular language, however, you may want a specialized Unicode font for that language. In our sample above, we display the Unicode for the Japanese character 30B0, but it is not as pretty as the picture on the code page. Getting a specialized Japanese font would likely work better.
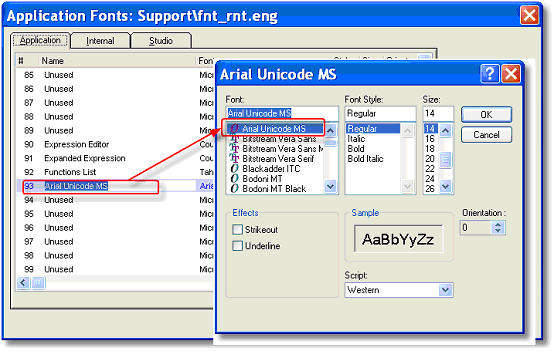
Once you install the desired Unicode font on your computer, you need to point to it in Magic xpa. Select that font in Options->Settings->Fonts, and use it whenever you need a Unicode font. In our example, font 93 is Unicode.
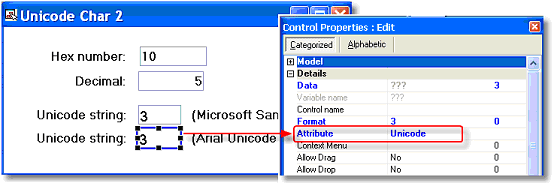
Also, you need to be sure the Unicode characters are in a field with a Unicode attribute. If you move the Unicode data to an Alpha or Blob field set with Ansi content type, they will not display properly.
The Online and Rich Client Samples projects (program UN01 and RUN01)
